















News & Resources
Case Study
How Alpha Omega used Generative AI to make 60,000 legacy documents discoverable
Author: Manu Mahendru with Alpha Omega Data & AI Center of Excellence

August 21, 2024
1. Background
Alpha Omega is at the forefront of assisting government clients in experimenting with and integrating generative AI solutions to enhance their mission objectives. While many of our customers have already strategically adopted generative AI to streamline specific workflows or implement significant process changes in complex environments, others require a more cautious and targeted introduction to these technologies. This article explores the workflow with one such customer.
In the scenario described below, a government agency sought to gain initial experience with generative AI through experimentation before making broad strategic and policy decisions regarding its use. At this juncture, Alpha Omega’s Data & AI Center of Excellence (CoE) identified a pertinent use case to address a real problem faced by the agency, showcasing the capabilities of generative AI in a specific context. By thoroughly understanding the relevant data, including its flow, lifecycle, and historical context, and aligning it with the agency’s strategic and tactical objectives, our Data & AI CoE developed a simple yet cost-effective minimum viable product (MVP) which also had a tangible and positive impact on the agency’s end users.
2. The Need for Document Categorization
As part of its research and development objectives, the agency generates approximately 2,000 scientific documents annually. Agency staff across the United States follow a process that organizes these documents within a system of record. A critical component of this workflow involves manually assigning each document one or more labels from a predefined category hierarchy. Staff members select these labels based on their understanding of the scientific content in the document.
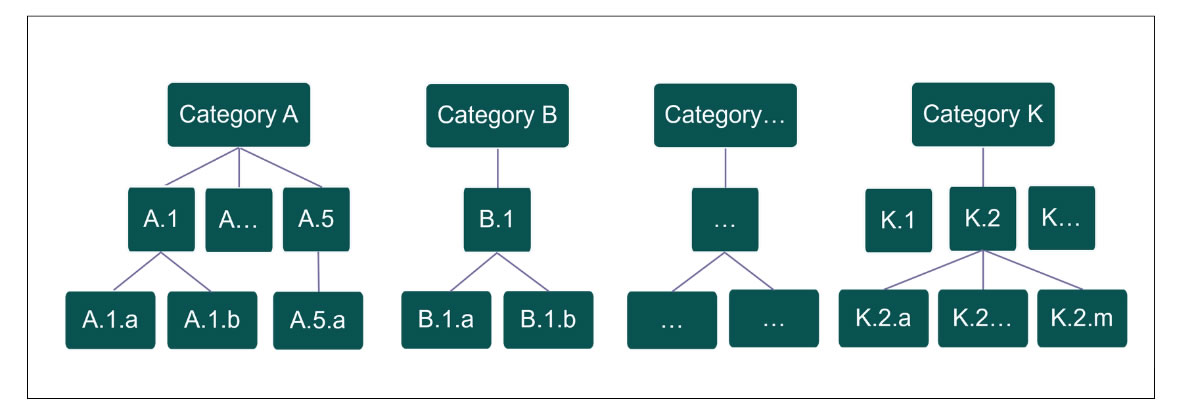
This categorization process enables the documents to be accessible within the agency’s downstream knowledge portal, allowing users to locate documents by navigating through the hierarchical categories. Users can find documents categorized under broad categories such as “Category A,” as well as more specific subcategories like “Category A.5” or “Category A.5.a.”
2.1 The Challenge
While the manual process performed by the staff is manageable for categorizing a few thousand new documents annually, the agency faces a significant challenge with its legacy documents. The category hierarchy was established only three years ago, yet the agency has approximately 60,000 legacy documents produced since the early 1900s. When these documents were initially added to the system of record, there was no categorization framework in place. Consequently, these legacy documents lack the recently created category labels.
2.2 Why It Matters
The absence of categorization for the legacy documents renders them inaccessible to users navigating the information hierarchy in the downstream knowledge portal. Although a search feature based on other content can help surface relevant documents, users often prefer or find it easier to browse through the hierarchical categories. Additionally, users might not always know the specific terms to search for, making it difficult to retrieve these valuable historical documents. As a result, the uncategorized documents, which contain rich and valuable content with significant historical context, are underutilized and fail to fully support the agency’s mission.
2.3 Option 1: Manual Approach
One potential solution previously considered was to manually categorize these documents. This would have required staff members to comprehend, at least in summary, the scientific content of each document and then assign all appropriate labels from the category hierarchy. This approach would not only demand an excessive amount of staff time over several years but also produce results whose accuracy and completeness would be difficult, if not impossible, to evaluate objectively.
2.4 Option 2: Traditional Machine Learning Approach
Fundamentally, this issue represents a Natural Language Processing (NLP) challenge. In brief, NLP is a field that enables computers to understand and manipulate human language. Specifically, the task at hand falls within the ‘Text Classification and Categorization’ subdomain of NLP, and more precisely, it is a ‘Multilabel Classification’ problem (as opposed to Single-label Classification, because each document can have multiple labels).
Traditional NLP techniques for addressing such issues have been around for years. A possible solution using traditional NLP would involve developing and maintaining a bespoke system, necessitating a team of software and machine learning (ML) engineers. While a well-developed NLP solution can achieve high accuracy, the complexity of this problem, which requires the models to deeply understand the scientific content in the documents, makes the creation and evaluation of these models both time-consuming and costly. After conducting a straightforward cost-benefit analysis with the assistance of our Total Solutions Group (TSG) and considering the customer’s priorities for the upcoming years, it was concluded that developing a traditional NLP solution was not the optimal choice at this time
3. The Simplest Possible Solution: Leveraging Large Language Models
Since about mid-2023, the availability of highly capable Large Language Models (LLMs) as a service has enabled us to address such challenges with more streamlined and efficient solutions. LLMs are tools that have been trained on vast amounts of human language in various contexts. This extensive training equips these models with human-like reasoning abilities, allowing them to adapt to different contexts with high accuracy and effectiveness, outperforming traditional, customized NLP solutions.
The advantages of using LLMs are significant. They eliminate the need for time-consuming and costly development and maintenance of custom models. Investments made in solving one type of natural language problem with LLMs can also be leveraged to address similar challenges in the future, providing a versatile and scalable approach.
Given that the agency was just beginning to explore Generative AI, our TSGdesigned a solution that was tightly limited in scope. However, considering the agency’s trajectory towards making strategic decisions on Generative AI usage policies, compliance, and governance, it was crucial for our solution to be adaptable to any future constraints imposed by LLM and cloud providers.
We outline this straightforward solution below. For brevity and clarity, we focus only on key evaluation, implementation, and architectural decisions.
3.1 Talking to LLMs Today
Before delving into the solution, it is crucial to emphasize that publicly available LLMs, both proprietary and open source, are continuously being enhanced by their vendors. This is a rapidly evolving field, and many of the LLMs we evaluated have already been superseded by newer versions. We anticipate that LLMs will soon be capable of comprehensively and accurately understanding massively large documents, even those containing specialized domain content. While some vendors claim their LLMs can already process extremely large amounts of content in a single attempt (referred to as a very large context window in generative AI terminology), our practical experience has shown that these LLMs often fail in subtle ways. The failures depend on the type or structure of the content being analyzed and the specific questions posed to the LLM.
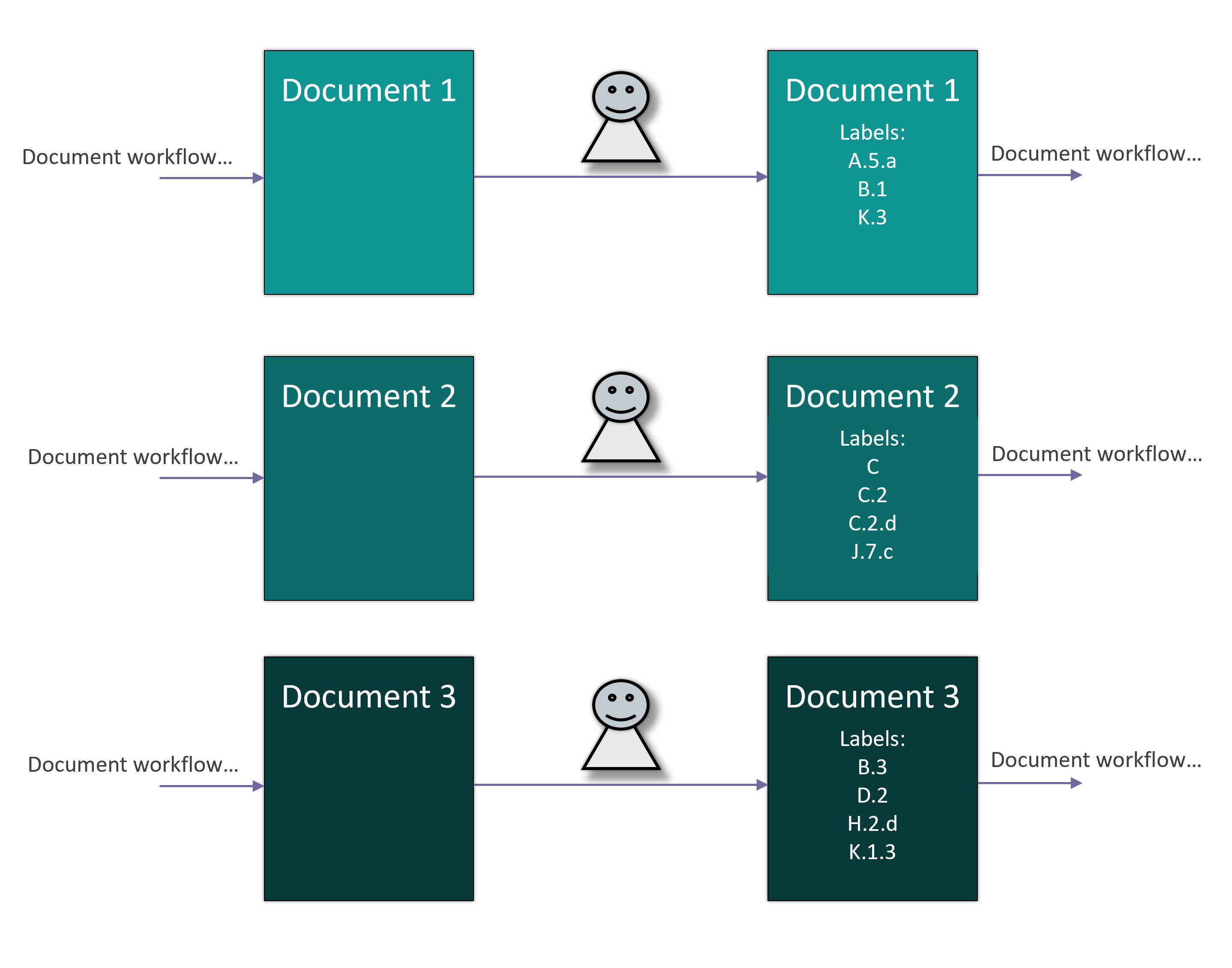
Although this issue is likely to diminish in the coming months and years, at the time of our evaluation, LLMs performed best when provided with appropriately cleaned, limited, and focused content. Therefore, for the categorization task at hand, we opted not to submit entire documents to the LLMs. Instead, we chose to use specific content extracted from the documents. Fortunately, as part of the existing document workflow, these “content elements” had already been extracted and stored in the system of record’s database. These elements included the “Title,” “Abstract,” and “Summary.” Importantly, these content elements had been manually reviewed during extraction, allowing us to bypass the need to read and parse individual document files and instead focus on the reviewed and specific data to be sent to the LLMs.
3.2 Task 1 of 3: LLM Evaluation and Selection

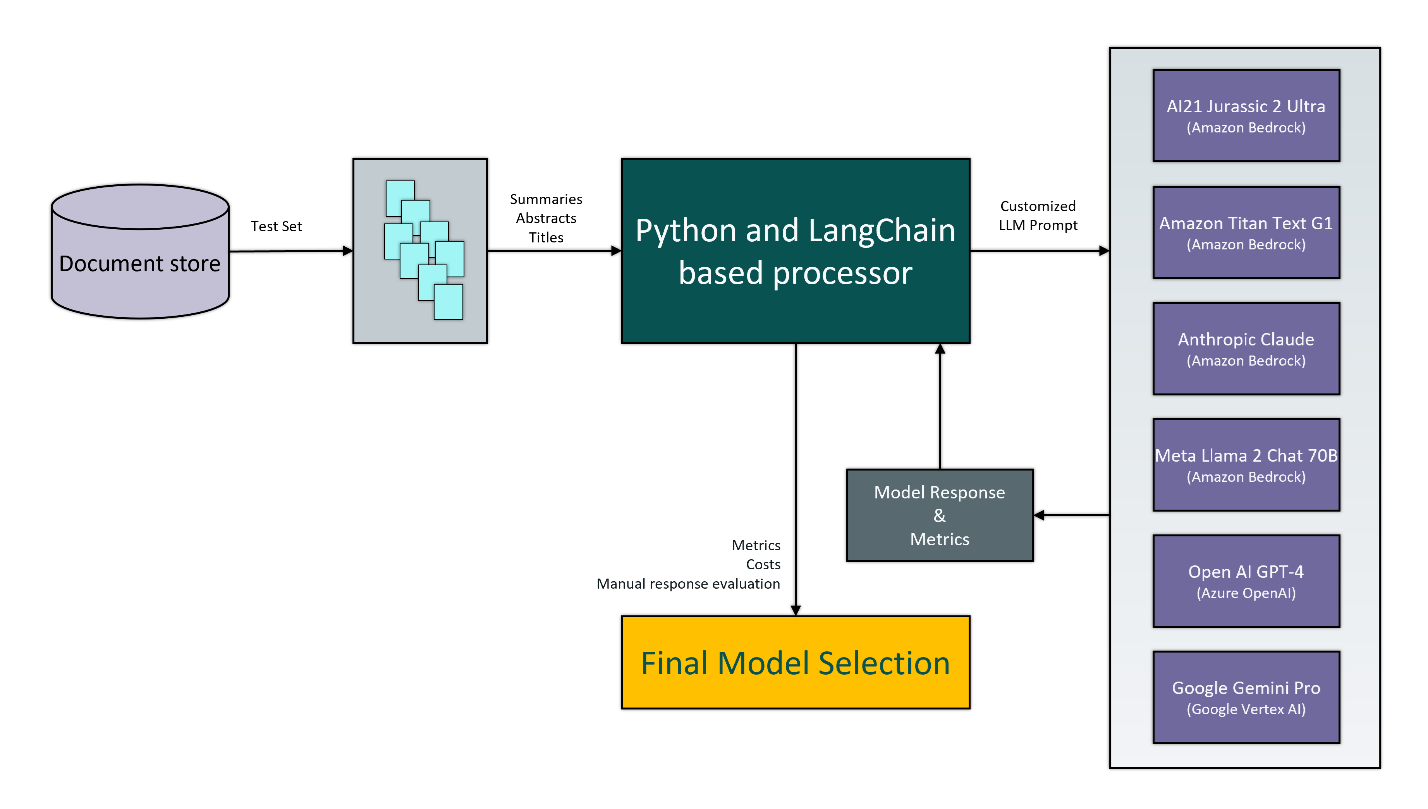
The initial task was to evaluate multiple publicly available LLMs and compare the results they produced for a set of documents previously categorized manually by our customer’s domain experts. For this evaluation, we selected 300 documents, referred to in machine learning terminology as the ‘Test Set’.
After consulting with the customer, TSG decided to develop an evaluation tool that would integrate with various LLM and cloud provider Application Programming Interfaces (APIs). We aimed to design the tool with a modular architecture, enabling the selected LLM’s integration to be easily extracted and deployed as a container image or serverless function on any of the three major public cloud providers. To achieve this, we chose the Python-based LangChain library. Despite some known drawbacks, LangChain provided a suitable starting point for easier integration with both existing and future LLMs.
The selection criteria for the LLMs to be evaluated were based primarily on their availability as a service via public cloud providers, published benchmark results, no requirement for fine-tuning before use, and costs. To expedite development, we opted not to deploy an open-source LLM ourselves but instead use public cloud-provided LLM-as-a-service solutions that did not require fine-tuning to produce acceptable results. This decision was driven by the fact that the agency already had production workloads on major cloud providers, allowing us to leverage their data protection, controlled access, and network isolation capabilities. Additionally, the serverless and managed infrastructure offerings from these providers enabled us to focus on the LLMs and the application we intended to build, rather than managing the underlying infrastructure.
3.2.1 Criteria for LLM Selection and Final List
Data privacy is a crucial consideration when evaluating third-party services. Given that the agency was formalizing its generative AI policy and compliance guidelines, TSG recognized that the data used in this project needed to be publicly available information. This criterion was a significant factor in selecting this use case for the agency’s initial experimentation with Generative AI. All the content sent to the LLMs was already publicly accessible, and the responses generated by the LLMs would also become public information. Furthermore, adhering to explicit cloud provider policies and limiting ourselves to LLM-as-a-service offerings from the three major public cloud providers ensured that the agency’s data would not be used to further train the underlying LLMs.
Latency, barring extremely poor performance, was not a primary concern for this project. Our goal was to develop a solution whose per-response performance (or lack thereof) would not directly impact any other supported service. Since our application and data (the content elements) would already reside within the cloud provider’s network before any LLM calls, and data would not traverse the public Internet, the main latency-inducing factors would be the LLM itself and any throttling due to the service limits imposed by the cloud provider (e.g., maximum requests per minute, maximum tokens per minute).
Vendor lock-in was also a minimal concern, as the primary objective was to create a batch application for a one-time categorization of the documents.
This flexibility in our criteria was intentional and necessary to ensure we evaluated LLMs that could deliver effective results quickly and economically. Based on these criteria and the availability of LLMs at the time, we evaluated the following models:
- Anthropic Claude 2 via Amazon Bedrock service (superseded by Claude 3 and 3.5)
- Llama 2 Chat 70B via Amazon Bedrock service (superseded by Llama 3)
- AI21 Jurassic 2 Ultra via Amazon Bedrock service
- Amazon Titan Text G1 via Amazon Bedrock service
- OpenAI GPT-4 via Microsoft Azure OpenAI service (superseded by GPT-4 Turbo and GPT-4o)
- Google Gemini Pro 1.0 via Google AI (superseded by Gemini 1.5 Pro and Gemini 1.5 Flash)
3.2.2 Customized Prompts
A ‘prompt’ is the input content submitted to an LLM, while a ‘response’ is the content returned by the LLM. The structure of prompts is highly specific to each LLM. We quickly realized that attempting to use a single prompt format across multiple LLMs was ineffective. Although certain content elements could be abstracted, we developed customized prompts for each LLM under evaluation. These prompts included specific instructions for the task, the content elements (title, abstract, summary), and the allowed label hierarchy.
For the task, each LLM was instructed to select the most appropriate labels for the document, restricted to the official category hierarchy. The LLM was also instructed to return a JavaScript Object Notation (JSON) response in a schema compliant with our requirements, using three example responses to guide it (a technique known as the ‘few-shot approach’ in generative AI).
The LLM responses were then parsed and evaluated for validity. Any invalid label responses were logged and followed by a second request. This was repeated for each document in the test set, the responses were stored, and quality metrics were generated for the model based on the prior manual categorization of the test set.
This process was repeated for all LLMs in the evaluation set.
3.2.3 Evaluation Criteria
After generating results from the different LLMs, the next step was to evaluate these results to determine which LLM would deliver the best performance across the 60,000 legacy documents. One possible approach was to have the customer’s domain experts review the inputs and outputs from each LLM and select the one they believed would be most effective. However, this method would be highly subjective, influenced by the reviewers’ past experiences, understanding of various scientific domains, and personal biases.
Instead, we sought a more objective measure of performance for our LLMs. Even if it did not directly decide the LLM to use, it would provide a clear, unbiased evaluation to present to the reviewers (the customer’s domain experts). While the specifics of machine learning model performance measures, particularly for multilabel classification tasks, are beyond the scope of this article, we will outline the two main properties that influenced our final evaluation criteria.
In our evaluation using the 300 test documents, ‘False Positives’ were the incorrect labels that the LLM assigned to a document compared to the labels manually assigned previously. ‘False Negatives’ were the missing labels that the LLM failed to assign but should have, based on the manual categorization. ‘True Positives’ were the correct labels assigned to a document that matched the manual assignments.
To determine the best LLM, we first needed to address a critical question: Which is worse for us, more false positives or more false negatives?
A False Positive, or incorrect label, would result in a user finding a document in the agency’s downstream portal that appears relevant based on the information hierarchy but turns out to be unrelated to their needs. This scenario would frustrate users and diminish their trust in the portal’s categorization and ability to bring forth relevant documents.
Conversely, a False Negative, or missing label, would mean the document is not accessible via a specific category page in the downstream portal. This was the situation that already existed for the legacy documents.
Overall, we concluded that a high number of false positives (incorrectly assigned labels) would result in a significantly worse user experience compared to a high number of false negatives (missing labels). False positives would mislead users into accessing irrelevant documents, whereas false negatives would only maintain the current accessibility limitations of the legacy documents. In other words, we prioritized being “right” over “finding them all.”
Thus, our evaluation criteria focused on a measure known in machine learning as ‘Precision.’ Precision is the ratio of true positive labels to the total labels found: true positives / (true positives + false positives). A higher precision value indicated better objective performance for our task, guiding us to the most suitable LLM for the job.
3.2.4 (Some of the) Lessons Learned
Developing a Python application with LangChain and other supporting libraries and deploying it in a test environment that integrated with each of the LLMs, was straightforward and like other tightly focused services that integrate with a few external APIs. The most time consuming part of the development process was tweaking the prompts. As is typical in generative AI development, this was a highly empirical process.
Even after setting parameters on the LLMs to reduce or eliminate the randomness of their responses, LLMs still respond slightly differently to minor prompt adjustments. When a LLM’s response is used by a downstream service or system, it is crucial to monitor and control this response carefully. To ensure this, we instructed the LLMs to respond only with valid JSON conforming to a specific schema. Additionally, we implemented mechanisms to retry “bad” responses and log secondary failures for separate batch processing later. This allowed us to catch errors either during the parsing of the (invalid) JSON response from the LLM or later, when the valid JSON response contained invalid content (e.g., a hallucinated category label that did not exist in the official category hierarchy). These types of errors informed prompt adjustments for the different LLMs we evaluated, guiding the system to produce a low percentage of errors and hallucinations.
3.3 Task 2 of 3: Labeling Legacy Documents
Alpha Omega’s Data & AI CoE, in consultation with the customer’s domain experts, selected Anthropic’s Claude 2 language model (hosted on Amazon Bedrock) based on its quality metrics, cost, and API availability on the preferred cloud provider.
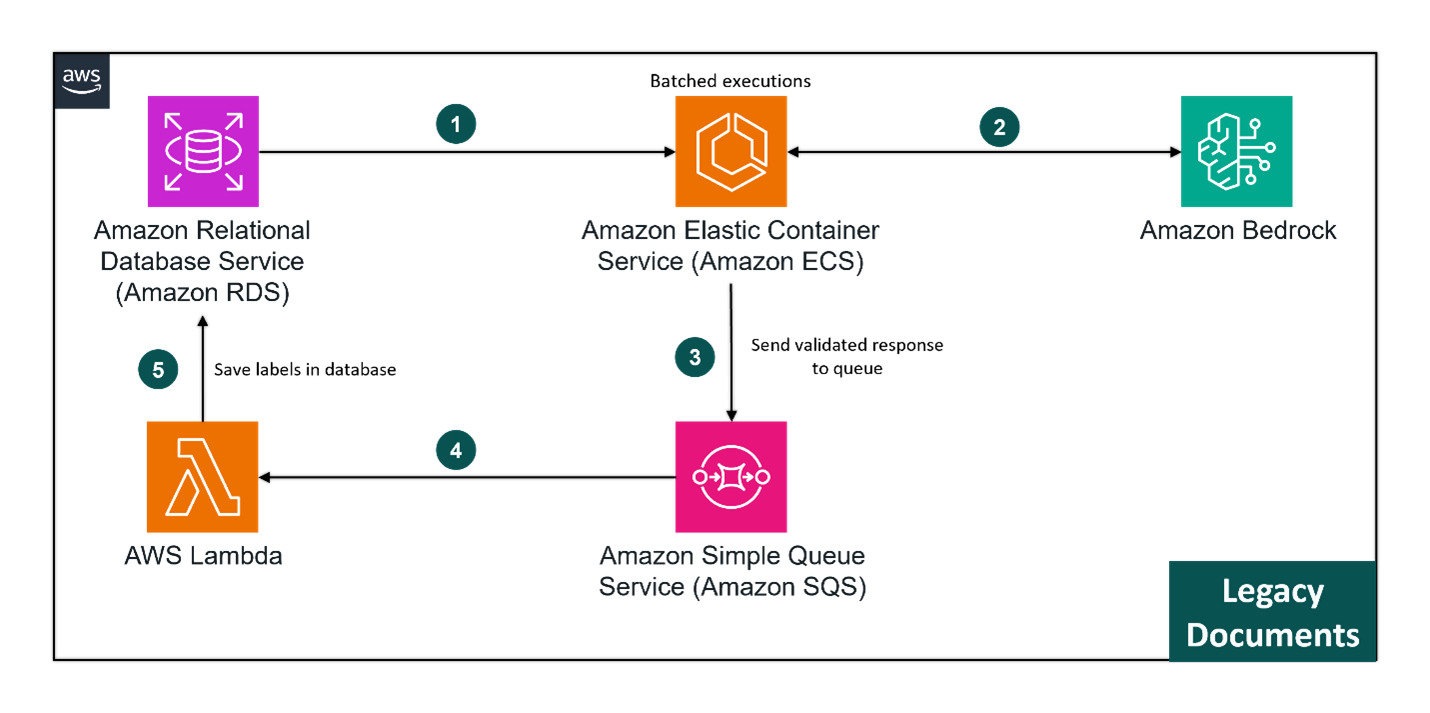
Given that this was intended to be a batch application, estimated to be run only a few times, we opted to deploy it on AWS Elastic Container Service (ECS). This approach facilitated parallel execution on batches of a few thousand documents at a time. Controlled parallelism not only increased the labeling speed but also ensured that Amazon Bedrock and LLM service limits were nearly maximized without exceeding thresholds that would trigger throttling.
The choice of ECS minimized deployment complexity, compute costs, network costs, and latency for calls to Amazon Bedrock.
All responses were validated, and any invalid responses or hallucinated labels were saved in a temporary DynamoDB table for secondary processing. Due to the extensive prompt tweaking during development, there were fewer than 14 hallucinated label generations from over 60,000 invocations, resulting in an error rate of 0.023%.
3.4 Task 3 of 3: Labeling New Documents
The primary objective of our project was to develop a batch solution for labeling legacy documents, which was successfully achieved with the implementation described above. However, due to the positive impact from this batch processing task, we expanded the solution to address the manual labeling of new documents.
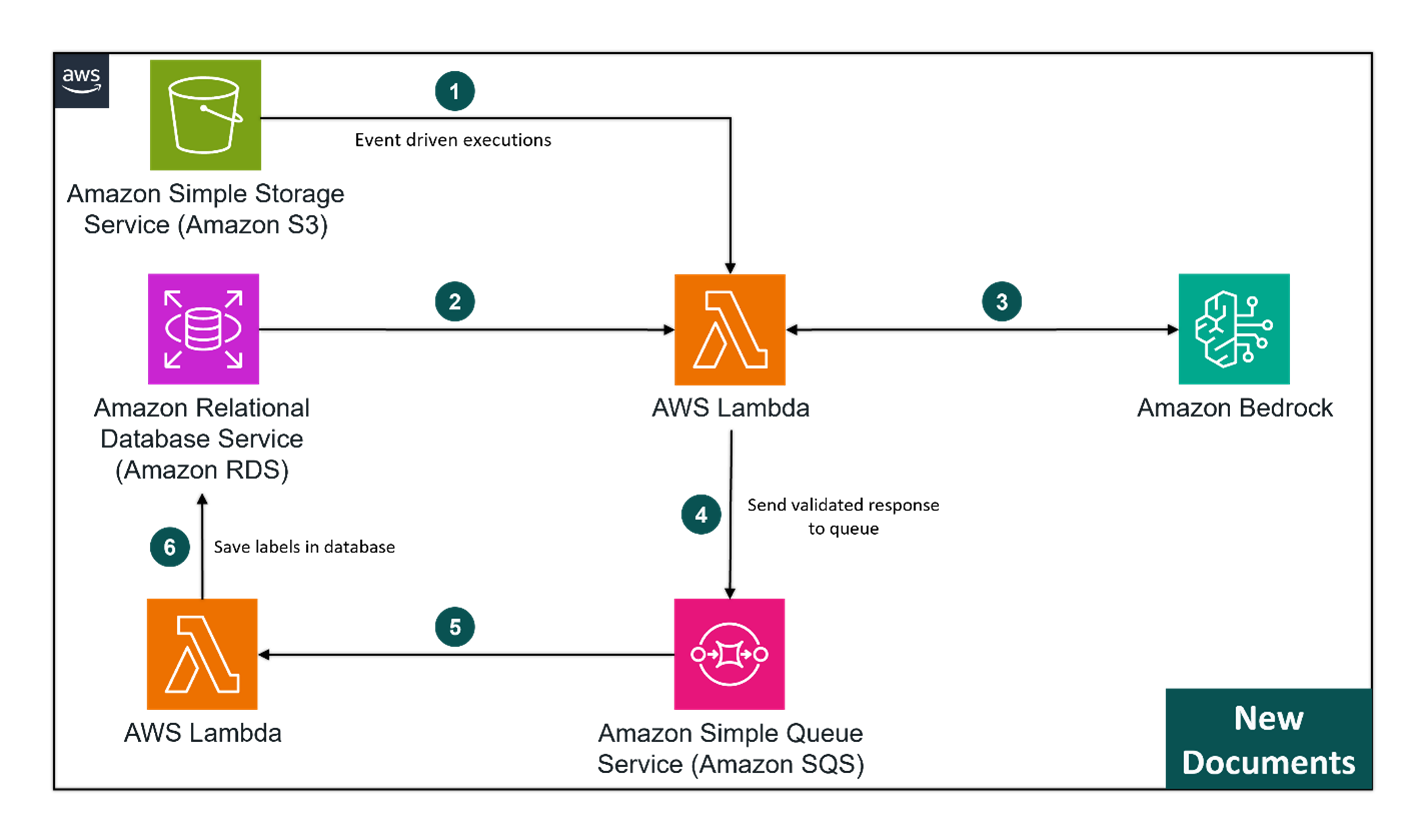
After minor modifications to the original solution, including additional exception handling and monitoring capabilities, we integrated the solution’s label generation task into the regular workflow for new documents. Now, when a document is placed in its storage location (Amazon S3), the solution is triggered to generate labels for the document. Later, when a staff member processes the document as part of their normal workflow, the LLM-generated labels are available for them to approve, reject, or overwrite. This approval or rejection is tracked as human feedback, which can be used to refine the LLM prompts and potentially inform the selection of the LLM itself over time.
Since document processing by staff members often occurs hours or days after a document is placed in Amazon S3, the label generation task does not need to be near real-time. This timing flexibility means that even if label generation takes minutes after the document is uploaded, it does not impact the overall document workflow.
Considering the agency produces approximately 2,000 such documents annually, averaging about 8 invocations per day (approximating 50 weeks per year with 5 working days), we chose AWS Lambda instead of the ECS service. This approach minimizes costs by eliminating the need to keep an ECS container running, even for a brief period, after a labeling task is completed.
4. Conclusion
This solution was developed in a matter of days and deployed economically using a container or function-based serverless architecture. Despite extensive integration with multiple datastores, no custom NLP solution was required. There was no need for traditional Retrieval Augmented Generation (RAG) involving vector stores or graph databases. Additionally, the selected LLM required no fine-tuning, as it was already capable of understanding the semantics of the content elements, the category hierarchy labels, and the specific responses we required.
What began as the agency’s exploration of Generative AI resulted in significant benefits. Through Alpha Omega’s innovative approach, many legacy documents were categorized swiftly, economically, and accurately within days, bypassing the need for a laborious manual operation that would have taken years. Ultimately, this solution delivered substantial value to the agency by making a wealth of legacy documents more accessible to its users.
Additional Resources
When the mission requires solving a challenge that’s never been done before, you can’t look to the status quo. Our agile, high-performing teams are at the forefront of emerging technologies and have the understanding and experience to apply disruptive innovation and cutting-edge solutions for government agencies.

